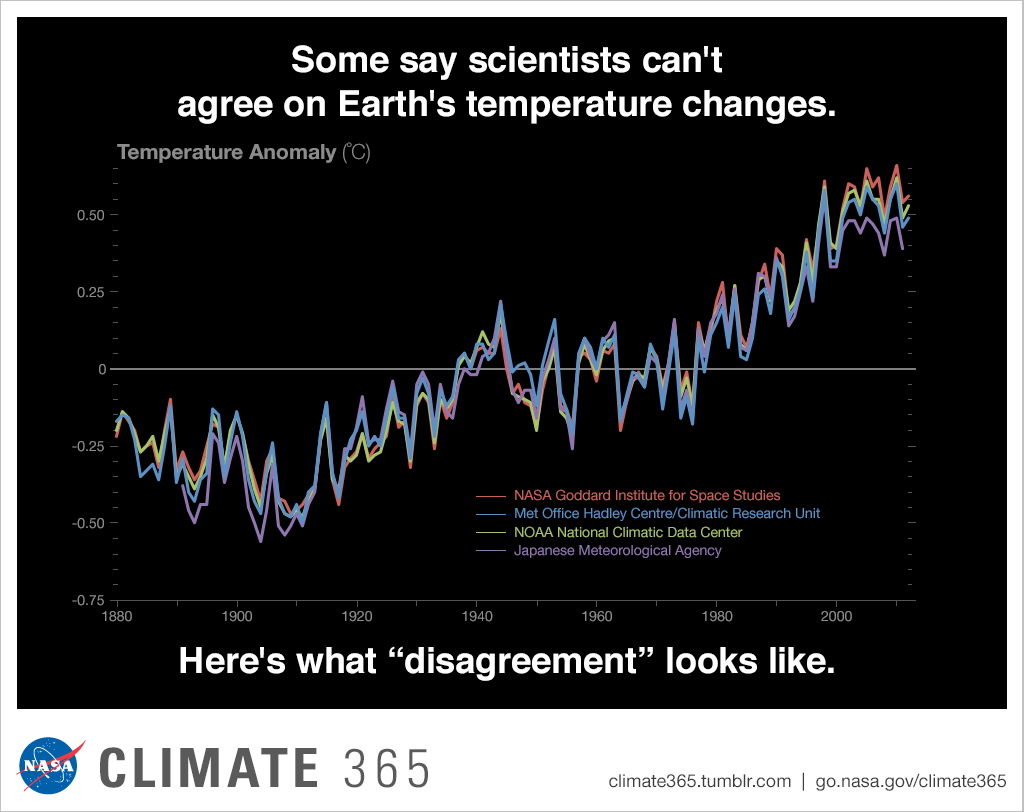
The Japan Meteorological Agency (JMA) produce its own version of the instrumental temperature record, which has until recently received little attention. NASA's Climate 365 put together a graphic to illustrate how little difference there is between the four primary global surface temperature datasets (Figure 1), but of course all the climate contrarians took from this was that JMA's data shows the least warming in recent years. Sources with a tendency towards motivated reasoning naturally concluded that it must be right.
Figure 1: The four main global surface temperature measurement datasets (Source)
Since it is now being more widely quoted, it is time we took a look at JMA data and investigate why they show less recent surface warming than the other three datasets. As we have seen before, an understanding of the coverage of a data set is critical in interpreting the resulting temperature series, so we will start by looking at the maps. The following figure compares the JMA temperature data with three other surface temperature datasets (HadCRUT4, NCDC and GISTEMP), the satellite data from UAH, and the reanalysis (weather model) data from NCEP/NCAR.

Figure 2: Coverage maps for various temperature series. Colors represent mean change in temperature between the periods 1996-2000 and 2006-2010, from +2C (dark red) to -2C (dark blue). Note that the cylindrical projection exaggerates the polar regions of the map.
Note that the coverage of the JMA data is rather limited - only 85% of the planet in December 2010, compared to 86% for HadCRUT4, 93% for NCDC and 99% for GISTEMP. As with HadCRUT4, coverage is very limited at the poles, which according to theory, models and observations have been warming more quickly than the planet as a whole. On top of this, land coverage is also limited in Africa and Asia - regions which have also been warming faster than the global average. On this basis we should expect the JMA data to show a rather lower warming trend than the other data sets. This is the case with a trend on 1997/01-2012/12 calculated from the map data of only 0.028°C/decade, compared to values from 0.043 to 0.080°C/decade for the other surface temperature records.
Given the limited coverage, what does this data set tell us about global surface temperatures? To answer this question we need to make an estimate of what the global temperature distribution would look like. The standard approach to this problem in geophysics is 'kriging', widely used in the oil industry (as well as by BEST) which provides an optimal estimate for values in the unmeasured regions. Unlike the less formal approach adopted by GISTEMP, kriging learns how the temperature varies over the measured region and uses that information to determine how far to extrapolate in the unmeasured region. The method is conservative in that map cells far from any observation revert towards the global mean.
One problem was noted while kriging this data: The calculation was extrapolating temperatures rather more aggressively than when applying the same calculation to the HadCRUT4 data. This is suggestive of some smoothing in the data - also evident in the figure above. The kriging parameters from the HadCRUT4 calculation were therefore used in place of those from the JMA data to produce a more conservative estimate of the global trend. The trends are compared below.
| Dataset | Coverage 2010/12 | Trend 1997/01-2012/12 |
| JMA | 85% | 0.028 °C/decade |
| NOAA | 93% | 0.043 °C/decade |
| HadCRUT4 | 86% | 0.046 °C/decade |
| GISTEMP | 99% | 0.080 °C/decade |
| JMA-krig | 100% | 0.083 °C/decade |
The best estimate of the global temperature trend from 1997/01-2012/12 using the JMA data is in good agreement with the GISTEMP estimate, and substantially higher than the remaining partial-coverage datasets.
The agreement between the global JMA and GISTEMP trends is remarkable, suggesting a very good agreement between the data. Unfortunately it's not quite that simple. The final figure of the HadCRUT4 paper shows a comparison of the 4 major temperature record using only co-located observations - i.e. the coverage of all the series is reduced to the cells common to all of them. The Hadley analysis shows that the co-located temperature series still shows JMA as a low outlier. JMA shows significant warming over Asia and Africa where its coverage is worst, and restoring these regions contributes to the large change in the JMA trend. However to fully attribute all of the differences between JMA and the other series will require more detailed study of the map data.
Is extrapolation of temperatures from one map cell to another really valid? This question is best answered using the data themselves. To do this we will have to use the HadCRUT4 data because the smoothing of the JMA data biases the results. We will take the HadCRUT4 data and further reduce the coverage by removing the observations from around the poles. The two possibilities - extrapolation and no extrapolation - are then tested by comparing their temperature estimates with the values obtained by using all of the data. For this test, map coverage is reduced by at least 2 cells in each column of longitude. This is equivalent to a distance of 1100km, comparable to the maximum extrapolation distance used in the NASA/GISTEMP method.
A temperature series is calculated from the reduced coverage maps only (i.e. the JMA approach), and from maps obtained by kriging the data to restore the omitted cells (the approach suggested here). The difference between each of these temperature series and the original HadCRUT4 series is a measure of the skill of each method at predicting monthly temperatures from incomplete data.
A sample month (Dec 2011) is shown for the original, reduced, and reconstructed maps in Figure 4.

he kriging reconstruction is generally more realistic, correctly reconstructing cool areas in central Asia and warm areas in the Arctic, although it does miss a cold feature north of Moscow. The Antarctic reconstruction show little variation from the global mean.
The difference between the monthly mean temperatures from each of the reconstructions and the original temperature is shown in Figure 5. Both the error, and the bias in recent years, are significantly reduced by using kriging over ignoring the missing regions.

The comparative skill of the two methods may be quantified by using the root-mean-square (RMS) difference between each of the reconstructed temperature series and the true temperatures. These are tabulated below:
| Method | RMS error/°C |
| No restoration | 0.033 |
| Kriging | 0.016 |
The RMS error of the kriging temperatures is less than half that obtained when ignoring the omitted regions. When using real data, extrapolating to restore omitted cells give a better estimate of the overall temperature than calculating a temperature estimate from the included cells only. The data themselves support the use of extrapolation.
Note: This analysis was originally performed using the JMA data, however the smoothing of the JMA data invalidated the results. The original material may be seen by viewing the html source of the post below this point.
The JMA temperature data, while it shows some regional differences, tells a very similar global story to NASA's GISTEMP but with substantially reduced coverage. The data themselves tell us that confining a temperature observation to a 5x5° grid cell produces a noisy and biased estimate of global temperatures. When an approriate reconstruction method is used to produce an unbiased estimate of global temperature, the JMA data shows very similar results to NASA's GISTEMP, which is the fastest warming of the offical surface temperature records.
Posted by Kevin C on Tuesday, 12 February, 2013
 |
The Skeptical Science website by Skeptical Science is licensed under a Creative Commons Attribution 3.0 Unported License. |

