






























 Arguments
Arguments








































How reliable are climate models?
What the science says...
| Select a level... |
 Basic
Basic
|
 Intermediate
Intermediate
| |||
|
Models successfully reproduce temperatures since 1900 globally, by land, in the air and the ocean. |
|||||
Climate Myth...
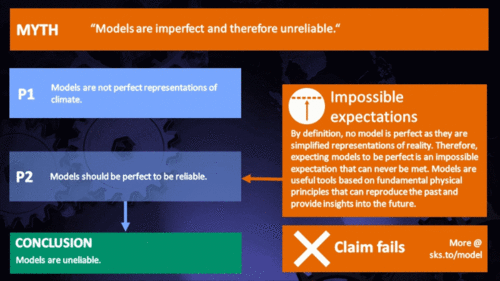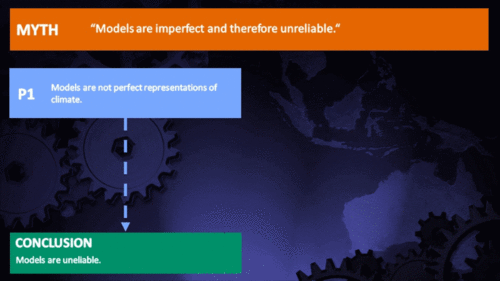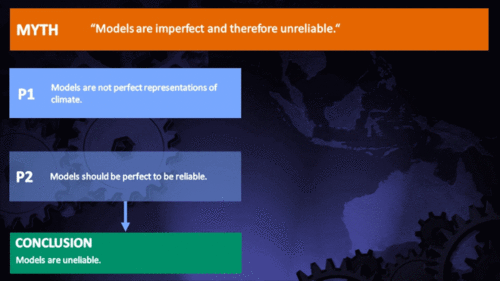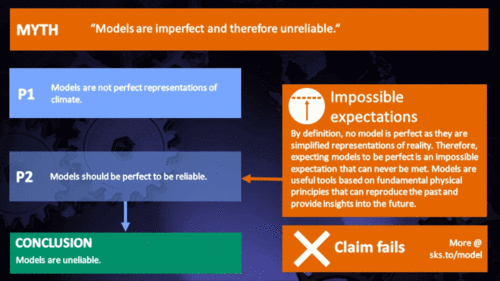
Models are unreliable
"[Models] are full of fudge factors that are fitted to the existing climate, so the models more or less agree with the observed data. But there is no reason to believe that the same fudge factors would give the right behaviour in a world with different chemistry, for example in a world with increased CO2 in the atmosphere." (Freeman Dyson)
At a glance
So, what are computer models? Computer modelling is the simulation and study of complex physical systems using mathematics and computer science. Models can be used to explore the effects of changes to any or all of the system components. Such techniques have a wide range of applications. For example, engineering makes a lot of use of computer models, from aircraft design to dam construction and everything in between. Many aspects of our modern lives depend, one way and another, on computer modelling. If you don't trust computer models but like flying, you might want to think about that.
Computer models can be as simple or as complicated as required. It depends on what part of a system you're looking at and its complexity. A simple model might consist of a few equations on a spreadsheet. Complex models, on the other hand, can run to millions of lines of code. Designing them involves intensive collaboration between multiple specialist scientists, mathematicians and top-end coders working as a team.
Modelling of the planet's climate system dates back to the late 1960s. Climate modelling involves incorporating all the equations that describe the interactions between all the components of our climate system. Climate modelling is especially maths-heavy, requiring phenomenal computer power to run vast numbers of equations at the same time.
Climate models are designed to estimate trends rather than events. For example, a fairly simple climate model can readily tell you it will be colder in winter. However, it can’t tell you what the temperature will be on a specific day – that’s weather forecasting. Weather forecast-models rarely extend to even a fortnight ahead. Big difference. Climate trends deal with things such as temperature or sea-level changes, over multiple decades. Trends are important because they eliminate or 'smooth out' single events that may be extreme but uncommon. In other words, trends tell you which way the system's heading.
All climate models must be tested to find out if they work before they are deployed. That can be done by using the past. We know what happened back then either because we made observations or since evidence is preserved in the geological record. If a model can correctly simulate trends from a starting point somewhere in the past through to the present day, it has passed that test. We can therefore expect it to simulate what might happen in the future. And that's exactly what has happened. From early on, climate models predicted future global warming. Multiple lines of hard physical evidence now confirm the prediction was correct.
Finally, all models, weather or climate, have uncertainties associated with them. This doesn't mean scientists don't know anything - far from it. If you work in science, uncertainty is an everyday word and is to be expected. Sources of uncertainty can be identified, isolated and worked upon. As a consequence, a model's performance improves. In this way, science is a self-correcting process over time. This is quite different from climate science denial, whose practitioners speak confidently and with certainty about something they do not work on day in and day out. They don't need to fully understand the topic, since spreading confusion and doubt is their task.
Climate models are not perfect. Nothing is. But they are phenomenally useful.
Please use this form to provide feedback about this new "At a glance" section. Read a more technical version below or dig deeper via the tabs above!
Further details
Climate models are mathematical representations of the interactions between the atmosphere, oceans, land surface, ice – and the sun. This is clearly a very complex task, so models are built to estimate trends rather than events. For example, a climate model can tell you it will be cold in winter, but it can’t tell you what the temperature will be on a specific day – that’s weather forecasting. Climate trends are weather, averaged out over time - usually 30 years. Trends are important because they eliminate - or "smooth out" - single events that may be extreme, but quite rare.
Climate models have to be tested to find out if they work. We can’t wait for 30 years to see if a model is any good or not; models are tested against the past, against what we know happened. If a model can correctly predict trends from a starting point somewhere in the past, we could expect it to predict with reasonable certainty what might happen in the future.
So all models are first tested in a process called Hindcasting. The models used to predict future global warming can accurately map past climate changes. If they get the past right, there is no reason to think their predictions would be wrong. Testing models against the existing instrumental record suggested CO2 must cause global warming, because the models could not simulate what had already happened unless the extra CO2 was added to the model. All other known forcings are adequate in explaining temperature variations prior to the rise in temperature over the last thirty years, while none of them are capable of explaining the rise in the past thirty years. CO2 does explain that rise, and explains it completely without any need for additional, as yet unknown forcings.
Where models have been running for sufficient time, they have also been shown to make accurate predictions. For example, the eruption of Mt. Pinatubo allowed modellers to test the accuracy of models by feeding in the data about the eruption. The models successfully predicted the climatic response after the eruption. Models also correctly predicted other effects subsequently confirmed by observation, including greater warming in the Arctic and over land, greater warming at night, and stratospheric cooling.
The climate models, far from being melodramatic, may be conservative in the predictions they produce. Sea level rise is a good example (fig. 1).
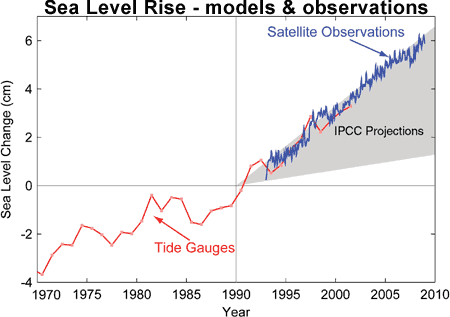
Fig. 1: Observed sea level rise since 1970 from tide gauge data (red) and satellite measurements (blue) compared to model projections for 1990-2010 from the IPCC Third Assessment Report (grey band). (Source: The Copenhagen Diagnosis, 2009)
Here, the models have understated the problem. In reality, observed sea level is tracking at the upper range of the model projections. There are other examples of models being too conservative, rather than alarmist as some portray them. All models have limits - uncertainties - for they are modelling complex systems. However, all models improve over time, and with increasing sources of real-world information such as satellites, the output of climate models can be constantly refined to increase their power and usefulness.
Climate models have already predicted many of the phenomena for which we now have empirical evidence. A 2019 study led by Zeke Hausfather (Hausfather et al. 2019) evaluated 17 global surface temperature projections from climate models in studies published between 1970 and 2007. The authors found "14 out of the 17 model projections indistinguishable from what actually occurred."
Talking of empirical evidence, you may be surprised to know that huge fossil fuels corporation Exxon's own scientists knew all about climate change, all along. A recent study of their own modelling (Supran et al. 2023 - open access) found it to be just as skillful as that developed within academia (fig. 2). We had a blog-post about this important study around the time of its publication. However, the way the corporate world's PR machine subsequently handled this information left a great deal to be desired, to put it mildly. The paper's damning final paragraph is worthy of part-quotation:
"Here, it has enabled us to conclude with precision that, decades ago, ExxonMobil understood as much about climate change as did academic and government scientists. Our analysis shows that, in private and academic circles since the late 1970s and early 1980s, ExxonMobil scientists:
(i) accurately projected and skillfully modelled global warming due to fossil fuel burning;
(ii) correctly dismissed the possibility of a coming ice age;
(iii) accurately predicted when human-caused global warming would first be detected;
(iv) reasonably estimated how much CO2 would lead to dangerous warming.
Yet, whereas academic and government scientists worked to communicate what they knew to the public, ExxonMobil worked to deny it."
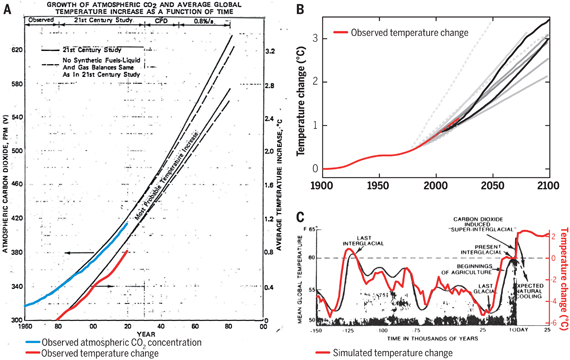
Fig. 2: Historically observed temperature change (red) and atmospheric carbon dioxide concentration (blue) over time, compared against global warming projections reported by ExxonMobil scientists. (A) “Proprietary” 1982 Exxon-modeled projections. (B) Summary of projections in seven internal company memos and five peer-reviewed publications between 1977 and 2003 (gray lines). (C) A 1977 internally reported graph of the global warming “effect of CO2 on an interglacial scale.” (A) and (B) display averaged historical temperature observations, whereas the historical temperature record in (C) is a smoothed Earth system model simulation of the last 150,000 years. From Supran et al. 2023.
Updated 30th May 2024 to include Supran et al extract.
Various global temperature projections by mainstream climate scientists and models, and by climate contrarians, compared to observations by NASA GISS. Created by Dana Nuccitelli.
Last updated on 30 May 2024 by John Mason. View Archives








I'm sorry about getting off topic..you're correct...however...i'm not the only one who is doing this for the responses. btw..you only win the argument if you convince the other person that they are wrong.
anyhow...after doing some more research...i ran into the article...
http://theresilientearth.com/?q=content/climate-models-%E2%80%9Cbasic-physics%E2%80%9D-falls-short-real-science
this is another view that is along the lines of what i have been exactly saying. my experience in modeling agrees with everything that is said in the article. and scientist need to explain why what is being said in this article is not correct. it didn't even touch on the dreaded (actually a serious problem) divide by 0 which is all to common in computerization of real world models.
the cmip5 models produce a wide range of results with a large error. the models are off what real world temperatures indicate. just looking cmip5 ar4 model graphs compare to real world temperature it appears that the models are more than two standard deviations off. I wanted to calculate this...but I was unable to find the necessary data to do so. if someone knows how to get this data or and some analysis of this i would very much like to review this.
if it is more than 2 standard deviations off this means that the math is questionable or the theory is questionable.
if the models produced a nice error i think 20% is acceptable..and the real world temperatures were following this within 2 standard deviations then this would significantly increase your confidence level. as things stand right now i do not have any confidence that the models results are accurate or properly represent the theory or math.
[Rob P] - Climate models show remarkable agreement with recent surface warming once natural variability and unanticipated changes in external forcings (such as increased volcanic sulfate aerosols) are taken into account.
I was unaware that reading blog posts by people who aren't climate scientists was considered research. Maybe you should read some actual papers.
tristan
here are the credentials of doug l hoffmann..blog originator
http://theresilientearth.com/files/dlhoffman.html
the man is highly qualified to evaluate computer models. you have to understand the the people who are writing and operating the programs for computer models are not climate scientists.
the field requires experts in many areas and not one person can be expert in all of them.
please present an argument addressing the issues cited
[JH] You are deluding yourself if you believe you know more about Global Climte Models (GCMs) than the commentors who are attempting to educate you on this thread. Please cease making dispariging remarks about their knowledge. If you do not, you will quickly relinquish your privilege of posting on this website.
I do not see any climate science credentials. Climate science modelling is a multidisciplinary topic, and as far as I can tell, Dr Hoffman has never published in the field of climate science. He only possesses one piece of the requisite expertise, and presents an opinion on a blog (and hence is not subject to the rigours of peer review and the scrutiny of others in the field).
On the other hand, we have papers like Risbey et al. (2014) that discuss the very topic at hand.
My question to you is this: Why do you eschew the published material on the topic and get your information from sources without the credibility that comes from working in a particular field?
Rhoowl claimed "the cmip5 models produce a wide range of results with a large error. the models are off what real world temperatures indicate. just looking cmip5 ar4 model graphs compare to real world temperature it appears that the models are more than two standard deviations off."
Multiple people have explained to you that your particular interpretation of the model results as "error" is incorrect. It appears that you continue to refuse to read explanations of what the model results actually are, and what the models actually are. To start with, you absolutely must read the Intermediate version of this "How Reliable Are Climate Models?" post. When a bunch of people on SkS tell you that you don't understand something, it is your responsibility to make at least the effort to read all of the original post on which you are commenting; some posts have Basic, Intermediate, and Advanced tabbed panes. If you don't trust what those blog posts say, I applaud you for your skepticism as long as you then read the peer reviewed original publications that those posts cite.
One source of variability in GCMs' results is differences in the models' constructions, not just their parameters. The CMIP5 ensemble of models is just that--multiple models, created by multiple people using different approaches. Those differences in models' constructions are not weaknesses! They are intentional--think of them as replications of experimental setups. Robust "replication" does not mean just rerunning an experiment with exactly the same setup. Instead it means running an experiment differently as long as, in principle, the results should be the same. Using differences in experiment construction and running is a test of whether the orginal experiment's results really were due to the posited phenomena or were due to otherwise uninteresting quirks in the experiment. Likewise, having differently constructed climate models safeguards against any one model's results being due to quirks in that particular model.
A good place to start learning about verification & validation (V&V) of climate models is at Steve Easterbrook's blog Serendipity. Steve is a computer scientist and engineer who used to be the chief scientist at NASA's independent V&V center, now is a professor, and does climate research. He has a good recent video of a TED talk (you should read the text surrounding that video on his blog), a short but good description of V&V, and a short description of massive and thorough comparisons of the outputs of 24 climate models. You would benefit from reading other posts of his that you can find by using his blog's Search field to look for "verification" or "validation."
Also useful for you to read is Tamsin Edwards's series of four short blog posts the links to which are near the top of her post Possible Futures.
Of course the bottom line is whether all those different models' results are the same. But "the same" does not mean "exactly the same." There is no absolute definition of "the same." Not 1 in 10,000. Not 2 standard deviations. Not 20%. This is true not just in climatology, but in every field. All models are wrong, but some are useful. For example, if you are trying to discover whether a drug helps an illness, and every experiment testing that shows it does not help, then it doesn't matter that some experiments show it makes no difference and some show it makes the illness worse. For the purpose of those experiments, the unanimous, sensible conclusion is that you should not give that drug to anyone with that illness.
It is necessary to define "the same" climate model results as "similar enough to suit the purpose to which these models' results are being put." But that's a topic for a future comment. First please address, narrowly, what I've written here.
Rhoowl wrote,
"you have to understand the the people who are writing and operating the programs for computer models are not climate scientists."
Producing a useful model of anything is 99% based on understanding the domain you are modelling, and 1% putting some code together. The idea that a non-climatologist who knows about programming is particularly well-positioned to comment on the success or otherwise of a climate model is nonsense. The idea that climate science has a lack of intelligent people versed in both the necessary domain knowledge and the coding skill is also nonsense. Sure, you mustn't assume that the climate modellers are infallible, but your starting assumption should be that the people trying to educate you on this site know much more about this than you or some programmer.
"btw..you only win the argument if you convince the other person that they are wrong."
This is probably the silliest comment I have ever read on this site. For a start, you are wrong if you see this exchange as a contest people are trying to win. The people responding to you are trying to educate you, and if you refuse to be educated that is a reflection on you, not on the validity of their responses. I see no evidence that anyone has failed to understand your points (which have all been discussed before anyway), but I see plenty of evidence that you have not actually stopped to consider what you are being told. Remainingly stubbornly ignorant and then calling that result a win or a draw is simply foolish.
@851
The blog post by Dr Hoffmann is wrong in so many ways. Here are just two points from it.
1. The illustration of rounding errors in computer programs would only be relevant if the errors have a systematic bias (i.e. they all rounded up or all rounded down). As Hoffmann's output shows they don't; the rounding errors are randomly signed and therefore will tend to cancel each other out, both within an individual run and between runs.
2. The discussion about modelling individual molecules in the atmosphere/planet is ludicrous; bulk matter has well defined properties that can be determined experimentally and used in a model without recourse to modelling individual molecules. We didn't know, or model, the individual atoms of the Apollo 11 space rocket, but that didn't affect our ability to predict its behaviour.
And two more ...
3. Hoffmann seems to think that global temperatures are inputs to GCM. This is just factually wrong
4. He makes the usual "denier" mistake of equating the atmospheric temperature record with the "global" temperature record (i.e he ignores 93% of the energy imbalance)
robp dr Roy spencer has also reviewed this his conclusion don't agree with you graph. Tristan dr spencer is a climate scientist.
http://www.drroyspencer.com/2013/06/epic-fail-73-climate-models-vs-observations-for-tropical-tropospheric-temperature/
Td I have already agreed that the scenarios spread was not an model error....there are errors in the models. I have also read the intermediate blog. What you pointed to as verification was reviewing past Enso from only 18 climate models. What About the other climate models. This appears to be a weak verification. He only matced the trend an not absolute values. I reviewed Steve easterbrook material. Much of what he professes is that science twist need to aek to the public in general terms so it is more understandible. Much of what he said didn't address the issues I am presenting.
leto I never claimed that the modelers do not have skill or infallibilty
Quite the opposite actually. The losing argument was started by someone else previously. Perhaps this was out of line.
Phil computers do have rounding errors, iteration problems with real numbers. Input has fudge factors. Is use fudge factors all the time when modeling. I enter objects that can't possibly exist just to make the program work...
after further reading about about the water co2 interaction it became clear that a grid resolution of 100km x 100km is too coarse to property model the cloud co2 interaction. The material is too anisotropic for that resolution. Zhou zhang bao and liu wrote a paper suggesting that grid resolution Be 1x1 mm. To properly model turbulence.. In the atmosphere. Obviously this would be an impossible task
[JH] Either English is not your first language, or you do not take the time to proof read what you have keyed in prior to hitting the "Submit" button. Either way, parts of your comment are nonsensical. In addition, some of your statements insult the intelligence of other commenters. If you keep going down this path, your future postings may be summarily deleted.
Rhoowl: Spencer followed up his claim that you linked, with another claim this time about "90 models" but likewise severely flawed. Hotwhopper clearly explained Spencer's biggest...um, "mistake"...of playing loose and fast with baselines. There is also the issue of Spencer falsely giving the impression that the RSS and UAH satellite trends for the tropics are consistent, when in fact UAH for the tropics is three times lower trend than RSS, and recently RSS has been shown to be correct in the tropics and UAH wrong.
Rhoowl: Your reply to my comment was not on the topic I had explained--differences between models. Since you either will not or cannot focus on a topic long enough to have an actual conversation, I'm giving up on you.
Jh I wish to reply to your comment and since it is off topic and is more personal in nature we should do this privately. My email is rhoowl at yahoo
[JH] Your request has been duly noted.
Rhoowl:
Indeed they do, which is why careful climate modeller programmers analyse their programs to ensure such errors are restricted, and the models (or their component parts) are tested to ensure they do not exert a undue influence. That they do would be obvious - a modelling program that produces results that are unduely influenced by rounding errors would give widely different results with very small changes to the input.
Whatever you may do, it does not follow that climate modellers do it too.
Tom Dayton @860, that Hotwhopper article is pretty damning of Roy Spencer's choices. What it does not mention was that 1983 was massively effected by the El Chichon volcano (which shows up the models), but that the effect in observed temperatures was cancelled, or more than cancelled by the 1983 El Nino in the observational record, which by some measures was stronger than the 1998 El Nino:
As ENSO fluctuations are random in time in the models, they do not coincide with observed fluctuations. The consequence is that while the volcanic signal was obscured in the observations, it was not in the models and the discrepancy between models and observations in 1983 was not coincidence. Nor was the greater relative temperature in UAH relative to HadCRUT4, as satellite temperature indexes respond more strongly to ENSO.
Spencer knows these facts. Therefore, his arbitrary choice of 1983 as the baseline year must coint as deliberate deception. He is knowingly lying with the data.
Klapper - Levitus et al seems to think there's sufficient data for estimating OHC, as does NOAA. But if you disagree, then you really don't have sufficient data to argue about model fidelity.
Klapper, at the moment, your dismissal of pre-Argo data seems to be an argument from personal incredulity. If you believe the Leviticus estimates of error margins on OHC to be incorrect, then can you please show us where you think the fault in their working is?
From Klapper - "I've looked at the quarterly/annual sampling maps for pre-Argo at various depths..."
Well, there are good reasons for NOAA to display 0-2000 data as pentadal (5-year) averages:
[Source - NOAA, slide 2]
What Klapper appears to be expressing with his short term trends and dismissal of earlier OHC data is a combination of poor statistics and impossible expectations about 'perfect' data.
@KR #867:
"...a combination of poor statistics and impossible expectations about 'perfect' data..."
I don't want "perfect data", I want the best data. I think all posters would agree that thanks to Aqua/Terra/GRACE/ARGO etc. we have the much better data available in the 20th century than previously.
Klapper @868... Absolutely. And the data we have a decade from now will be better than the data we have today. Today's data certainly doesn't invalidate past data nor would better systems in the future mean current data is bad. The data we have is just what it is at any given point in time. It's always going to be imperfect. Data is imperfect. Models are imperfect.
But again, this is why models are used to constrain those uncertainties. That's "Trenberth's tragedy." Our current systems can't fully account for all the heat in the climate system. That doesn't mean it's not there. That just means that our systems are inadequate.
What is abundantly clear, though, is that adding 4W/m^2 to the climate system is going to warm the planet in a significant and potentially calamatous way.
scaddenp: "If you believe the Leviticus estimates of error margins on OHC to be incorrect"
Hmm, I'm not a biblical scholar, but I don't recall seeing any estimates of error margins in that book...
Klapper - "...I want the best data"
As do we all. And the best data for the last half of the 20th century, while subject to higher uncertainties that current measurements, is worth attention.
Again, differences in the 5-10 (and, grudgingly on your part, perhaps 15) year periods you are looking at are short enough to be entirely unforced variation - with recent work on 21st century volcanic activity (not included in the CMIP5 forcings) that has direct implications for the TOA balance also worth considering. You've limited yourself to such a small dataset that frankly I cannot take any of your arguments seriously.
Rob Honeycutt @868:
With conservative governments in Australia and Canada, and a conservative congress in the US being so sure that the science is against them, that they are doing all they can to cut science budgets (particularly for research on global warming) I would not be sure of this.
@scaddenp #866:
"...But if you disagree, then you really don't have sufficient data to argue about model fidelity.."
I do disagree. Go to the NODC website. You can find a ocean heat data distribution mapping tool you can customize by period. For example, display 1500 metres depth for the period 1968 to 1972. Count the dots in a polygon formed by New Zealand, Ecuador, the Solomon Islands and the Antarctic Penisula. It's not hard to do. Keep in mind each black dot represents one sample, i.e. May 15, 1969.
You have maybe 4 or 5 single samples in this 5 year period between the equator and the Antarctic coast and 90 degrees and 150 degrees longitude west. This represents a huge area with essentially no data in a recent 5 year period.
For a shocking contrast, now retrieve the same depth for 1 year (2014) and try and estimate how many samples were retrieved.
..never fear, Instagram is here![starts worry mode]....
@KR #871:
"...You've limited yourself to such a small dataset that frankly I cannot take any of your arguments seriously.."
Although I'm skeptical of the data quality before this century for the deep ocean, I downloaded the pentadal OHC data and ran a 5 year running trend to convert ZJ to W/m^2 heat input on a global area basis. The results are as follows (TOA CMIP5 ensemble forcing vs NODC Pentadal heat content change, both 5 year periods):
1959 to 2000 - 0.23 W/m^2 from OHC, 0.49 W/m^2 from model forcing
2000 to 2010 - 0.51 W/m^2 from OHC, 0.95 W/m^2 from model forcing
While delta OHC is not global heat content change, it is the great majority of it. Two conclusions seem appropriate:
1. The better the observational data quality, the bigger the discrepancy between model hind/forecasts and,
2. The models run hot.
I can post the graph here if someone lets me know where I might post to the internet so I have a URL link.